Generative AI Shares a Lot in Common with Knowledge Management – How Do You Like Them Apples? A Recap of AALL 2023 in Boston
27 July 2023
In the week leading into the 2023 Annual Meeting of the American Association of Law Libraries, a survey of legal professionals contained a dire warning: two-thirds of respondents said they believed that law librarians and other knowledge workers in law firms could be replaced by artificial intelligence.
And artificial intelligence was set to take center stage at the annual meeting in Boston.
After the groundbreaking launch of ChatGPT in November 2022 and the spring 2023 release of OpenAI’s GPT-4, there were several product announcements, sessions, and panels targeting large language models (or LLMs) – was the annual meeting in Boston to be the high-water mark for information professionals in law firms and law schools?
The answer was a resounding no: if anything, the message from Boston was that law librarians and other allied information professionals might be more important than ever at the start of this revolution. Sessions on Generative AI were standing-room-only, with attendees sitting on the floor and standing in aisles to make room. There was more interest than ever in AI topics at this annual meeting.
The “Normalization of Mediocrity”?
In one of the first sessions of the conference, Exploring the Opportunities and Risks of ChatGPT in the Legal Industry, Ken Crutchfield from Wolters Kluwer, Jean O’Grady from Venable LLP, Courtney Toiaivao of Holland & Knight, and Vishal Agnihotri from Alston & Bird addressed the elephant in the room: Do we really believe the survey results that law librarians would be replaced by AI?
Panelists made it clear that the prompt engineering skills that make great legal information engineers are very similar to the skills of legal research. Start with a strategy. Understand sources of data. Look inside the black box and promote transparency. And verify sources.
O’Grady pointed out that there was a broad consensus that ChatGPT should never be used for legal research – its now-famous propensity to hallucinate meant that the technology wasn’t ready for professional use.
A key risk pointed out by Toiaivao: the “normalization of mediocrity,” as large language models are trained to create outputs that are effectively the statistical average of training data. Toiaivao pointed out that “average” outputs might make expert writing stand out even more.

Applying Lessons from Legal Research to LLMs
Just as in past legal information revolutions, relationships are crucial – and librarians have the longest-standing relationships with information publishers. This was especially clear in “Hunting and Gathering on the Legal Information Savannah,” a panel moderated by legal research expert Susan Nevelow Mart from Colorado Law. The panel featured Joe Breda from Bloomberg Law, Brian Mishmash from Thomson Reuters (which had just purchased Casetext), Vijay Raman from LexisNexis, and Ed Walters from vLex (fresh from a merger with Fastcase).

The panelists discussed how major legal research providers were using LLMs, as well as the difficulty of judging the quality of Generative AI results head-to-head. But all agreed that this is the beginning of a major shift in how legal professionals find information. And all of the panelists agreed that law librarians would be crucial in assessing the scope of training data and making sure that lawyers followed the same rigor with LLMs that they do with legal research sources.
Many of the lessons from AI are not new. In “Gold in Them Thar Hills: Docket Research and Litigation Analysis in State and Federal Courts,” Amanda Marshall from BakerHostetler and Michael Sander from vLex / Docket Alarm discussed the difficulty of tracking docket information from many different state and federal courts, and standardizing them into analytics. Sander pointed out that one of the most challenging tasks for Docket Alarm is to collect docket information in hundreds of different formats, across hundreds of millions of documents, and creating standard, SALI-compliant tags across all of them.
A Relationship of Trust
In session after session, experts said that what powers legal artificial intelligence is structured legal data, and law librarians are at the forefront of collecting and organizing that data. Annie Sterken from HBR Consulting and Damien Riehl from vLex / Fastcase discussed the standards movement in “Higher Standards: SALI’s Legal-Data Standardization Across the Legal Industry.”
The relationships are particularly important. In “Collaborating with Vendors: Marketing, User Needs, and Product Development,” Patrick Flanagan and Jaime Klausner from Baker Hostetler, Rachel Belthon of Thomson Reuters, Mike Bernier from Bloomberg, Andrew Christensen from Washington & Lee, Nina Steinbrecker Jack of vLex highlighted (to both librarians and publishers in attendance) the importance of building trust. Nina Jack underscored early collaboration in projects, alignment, and transparency (especially with disappointments) as especially key to building trust in those relationships.
Inside the vLex AI Labs
This was the first annual meeting since the merger of vLex and Fastcase, and the teams came together from around the world to showcase the combined company. There was a lot to cover, from a single library with the law of more than 100 countries, to the enhanced analytics of Docket Alarm, more than 1,000 secondary treatises in the collection, and much more. But it also permitted a sneak preview into the work of the vLex AI skunkworks team, which has been cooking a new research assistant using Generative AI.

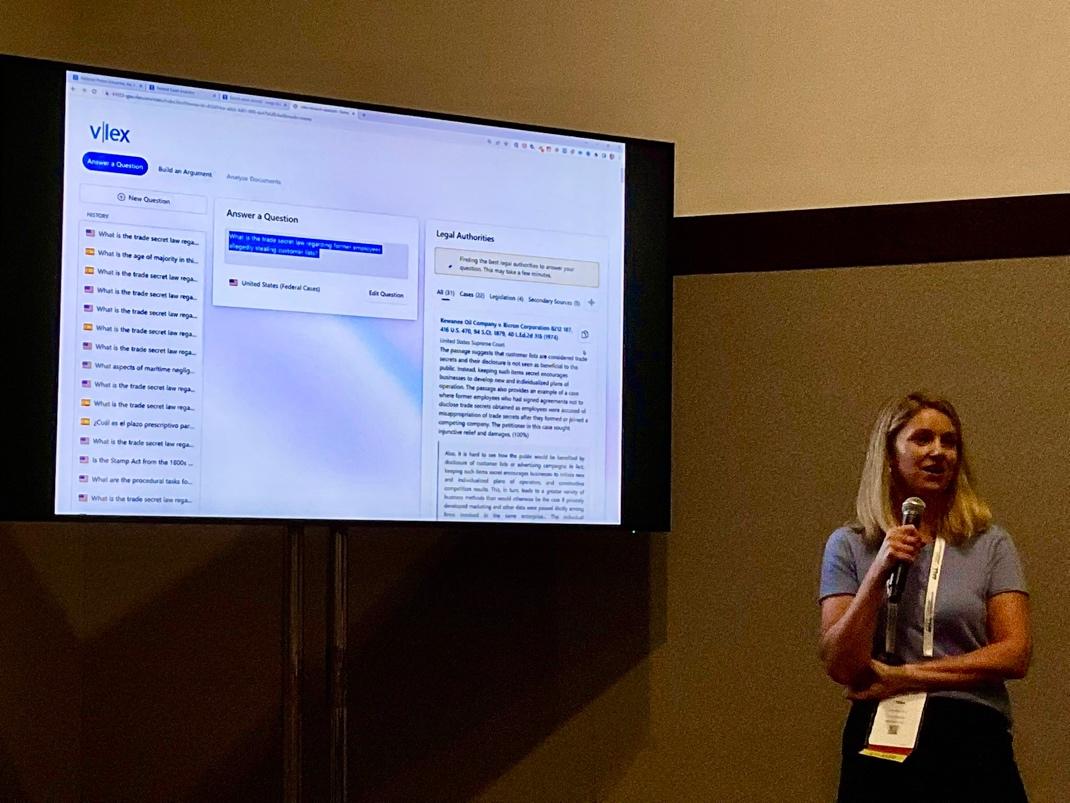
If there was one overarching theme for this year’s meeting, it was definitely Generative AI, and Nina Jack and Damien Riehl from the vLex team gave a preview of the new vLex Research Assistant, which uses Retrieval-Augmented Generation to answer legal questions in the U.S. and three other countries, citing primary and secondary sources linked directly into vLex.
A Profession Being Replaced by AI?
Jean O’Grady perhaps summed it up best at the end of a Sunday session. When asked if generative AI will marginalize law librarians, she responded that we’ve heard that many times before with other technologies, and it’s never been true. It wasn’t true with the World Wide Web. It wasn’t true with mobile apps or analytics, and it won’t be true with artificial intelligence, she said. O’Grady said that today the law library is everywhere that legal knowledge exists, and new opportunities similarly will arise everywhere.